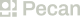Deploy an AI agent for predictive analytics in three weeks
Build accurate models and integrate them into your CRM – no data science needed.
We will estimate model deployment time with your current resources.
No data scientists needed
No coding required (only SQL)
Works well with raw/messy data
SOC2 and ISO Certified












Traditional data science is slow and expensive
Accelerate time to production and cut costs with

Data analysts can build ML models with SQL — without coding or data science skills
Chat-based use case identification extracted from thousands of popular predictive questions, proprietary LLM-based query generation and SQL co-piloting, built-in connectors and ETLs, automated ML optimization, built-in data validations and guardrails based on the analysis of hundreds of common pitfalls, and one-click deployment.
Automate your data prep in our secure platform
While no data prep can be fully automated, manual work can be significantly reduced by automating data cleansing, transformation, and feature engineering. The platform connects to raw data, handles missing values, and normalizes the data using patented data engineering algorithms that specialize in transforming raw tabular and transactional data into an ML-ready dataset. This includes the automatic extraction of labels, construction of samples, timestamping of entities, and avoiding data leakage.
Rapidly test and scale to succeed, supported by our ML engineers
The platform includes a GenAI-powered chat that helps craft predictive questions and translates them into SQL queries, while a team of highly experienced data science engineers, who have worked on numerous projects, is available to guide you in building the best AI strategy and ensuring success throughout the process.
Pecan’s platform is designed to empower business-oriented data leaders make a significant impact on revenue using Predictive ML.
Our team has supported countless predictive projects
and will ensure you bring immediate, measurable value to your organization.
Common data fields built on the platform











The platform processes raw data (e.g., transactional data) and accepts business prediction inputs provided by the user in natural language. We apply a wide range of data engineering and preparation techniques, leveraging our patented technology and LLMs. These algorithms analyze the raw data, identify relevant elements, and construct an ML-ready dataset tailored to the predictive question. Dataset construction includes creating entities/samples, extracting and computing the label, transforming the data into a rich time series, aggregating diverse features, and performing feature selection.
In parallel, it generates a SQL notebook using SOTA Gen-AI techniques to manage modeling definitions.
The platform continuously monitors for critical ML issues such as bias, leakage, overfitting, and drift to ensure the integrity of the data and the custom model.
From business need to measurable results
a typical roadmap with Pecan

KPIs most improved by Pecan's predictive models

We will estimate model deployment time with your current resources.
The algorithms automatically identifies outliers, anomalies and missing data and normalizes/imputes the data.
The platform continuously monitors and recalibrates models as new data is integrated, detecting accuracy-drops or data drifts and automating adjustments in real time,
typically achieving high predictive accuracy – up to four times better than rule-based logic from initial deployment.

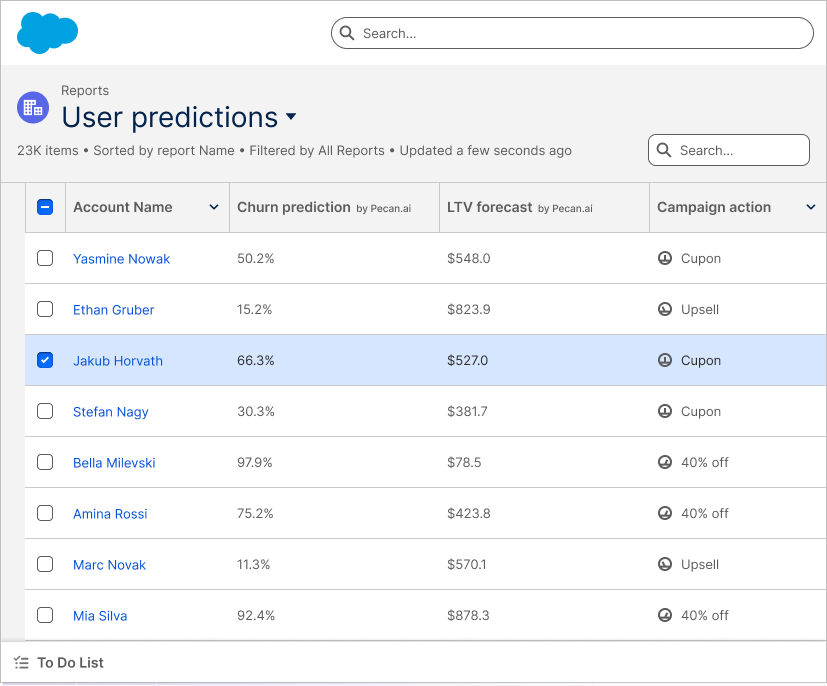
No annual commitment, transparent, predictable, and fair pricing
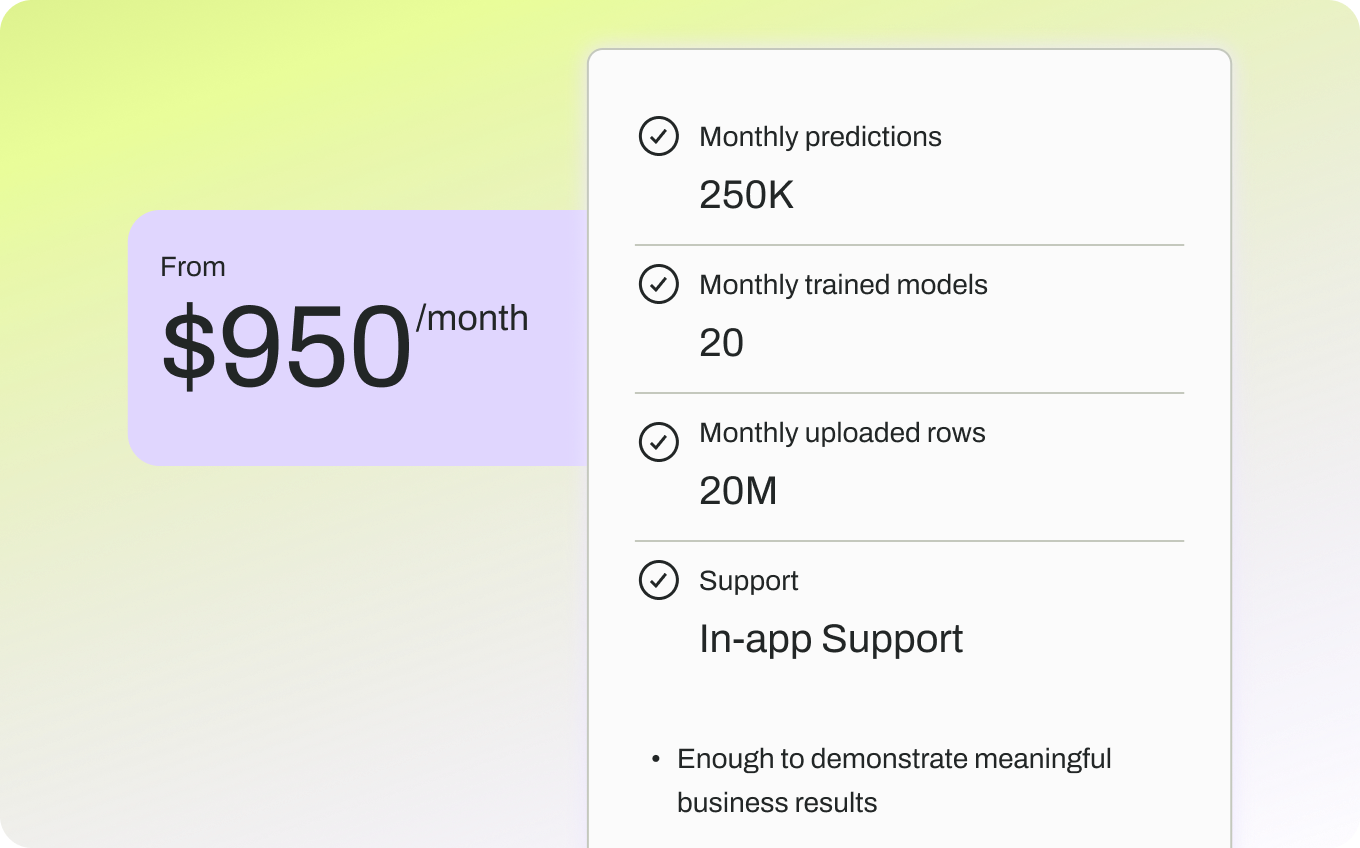
Universal compatibility with all data lakes, BI tools, and CRMs
-
“Pecan AI is faster. It's easier in terms of writing queries ... getting the features, the data points, the attributes that you need to train a machine learning model.”
-
“I was blown away by how simple it was for us to answer some fairly complex business questions — within minutes in some cases, and hours at the most.”
-
“We improved forecast accuracy in our seasonal business, and we have a deeper understanding of the variables that may influence a consumer demand signal.”
-
 "Pecan’s predictions informed our marketing efforts, helping us reach out to the right customers and allocate spend in the right places. The models were accurate in identifying which customers would more likely respond to our offers and make new purchases."
"Pecan’s predictions informed our marketing efforts, helping us reach out to the right customers and allocate spend in the right places. The models were accurate in identifying which customers would more likely respond to our offers and make new purchases." -
"Using Pecan to predict LTV has proven to be invaluable in optimizing our campaigns’ performance on iOS. Pecan’s unique approach for dealing with marketing measurement challenges under the SKAdNetwork has increased our visibility and allowed us to allocate budget to campaigns that generate higher ROAS."
-
“Pecan allows us to be more profitable and invest better. We are definitely able to buy smarter than we used to, and it's becoming a competitive edge.”
-
"The platform is very simple and easy to use. All I have to do is check or uncheck specific variables I want to include in the modeling process. If I need to bring in more data and build more datasets and connections, I can do that easily."
-
 "Pecan's Predictive GenAI framework is truly a game changer in making machine learning and AI capabilities accessible to the business team."
"Pecan's Predictive GenAI framework is truly a game changer in making machine learning and AI capabilities accessible to the business team." -
 "After our team examined various predictive analytics tools, we found that Pecan is truly a complete solution that's designed for analysts — from uploading data to generating predictions to enabling recommendations for actions to business units."
"After our team examined various predictive analytics tools, we found that Pecan is truly a complete solution that's designed for analysts — from uploading data to generating predictions to enabling recommendations for actions to business units."
Transform your data team from a cost-center to a revenue-driver
with one strategic move